SLM4SMB
a private, local AI receptionist for service businesses
A small-language-model appliance that reads service-business enquiry emails and books them on local hardware, with no cloud and no per-call fee.
A private AI receptionist that reads booking emails and puts them on the calendar, running on a cheap office computer with nothing sent to the cloud.
- Tested prototype
- 2026
What it is
Most small service businesses lose leads in a messy inbox. SLM4SMB reads each enquiry email, works out what the customer actually wants, and puts it straight on the calendar. It runs on a small computer in the back office, so customer details never leave the building and there is no per-message fee to a cloud provider.
The work
Context
Most enquiries arrive as mess
Service businesses run on enquiry email, and most of it arrives as mess: "Hot water's dead, can you come Tuesday arvo, 12 Marion Rd, 0411." Triaging that by hand is tedious and it drops leads. The two options on the market are both bad: do it by hand, or pipe your customers' details to a cloud AI that charges per call and takes their data off-site.
SLM4SMB is the third option. It is a small-language-model appliance that sits in a box in the back office, reads the enquiries, works out what the customer wants, and puts it on the calendar. Nothing leaves the building to a third-party AI, and there is no monthly fee.
What it does
A data-entry clerk, not a chatbot
It reads the mail and strips the noise down to the words the customer actually typed, then fills in a strict form rather than holding a conversation. The local model is forced to act like a data-entry clerk: is this a booking, what is the number, what service is needed. If it is unsure, it does not guess, it flags the email for a human.
It never does the date maths. If the customer wrote "next Tuesday arvo," the model copies that phrase and a plain, predictable Python routine resolves it against today's date. It books a tentative event, fires an immediate alarm on urgent words like "burst pipe," and resumes exactly where it stopped if you pull the plug mid-read.
The decisions that matter
Probabilistic where it helps, exact where it counts
The best call was the split between what is probabilistic and what is exact. The model only extracts date and time phrases verbatim, and every resolution to a real datetime happens in plain, timezone-aware Python. That is the first of ten invariants written before any code, and it is why the date logic is provably correct and fully testable with the model out of the loop.
Extraction is fail-safe by construction: schema-constrained decoding wrapped in a validate, retry, then needs-review loop that never raises, so a lead is never silently dropped. Idempotency is thread-scoped, so a reply updates the same event instead of double-booking, and the urgent alarm runs as a separate local channel because a subscribed calendar can take hours to refresh.
How it was built
One operator, a delegated agent team
One man, one machine, one day. The roles were split hard: I was the only decision-maker, Claude acted as technical director producing prompt blocks rather than code, and a Claude Code orchestrator dispatched scoped worker agents. What to build stayed mine; how to implement was delegated.
Eight phase-gated stages ran in bounded parallel waves. Workers ran in filesystem-isolated git worktrees, each owning a non-overlapping part of the tree, so merges were conflict-free by construction. Every gate was human-approved, the ten invariants lived in a shared constitution copied byte-identically, and a failing test suite was written before the code.
What is proven
A tough eval, and an audited orchestration
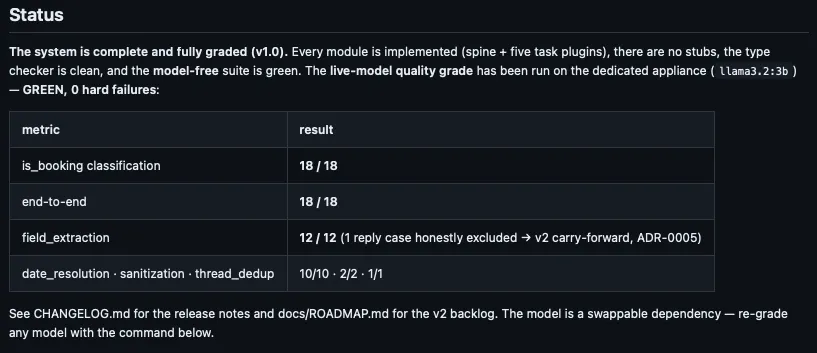
Sixteen hand-labelled fixtures cover the real spread: clean bookings, emergencies, fuzzy and day-month-year dates, threaded replies, web-form cruft, and a batch of non-bookings. The suite was proven failing first, and the deterministic core was verified with the model swapped out entirely. The eval caught real defects before they could ship, including a credential that would have leaked into the logs.
The marquee result is the orchestration audit: context isolation was proven from the agents' own tool-call transcripts and independently reproduced. The final board on Llama 3.2 3B, on a 2013 CPU-only iMac, was booking detection 18 of 18, end to end 18 of 18, field extraction 12 of 12, and date resolution 10 of 10.